一面
简单进行一下自我介绍
项目问题 (项目问题因人而异, 没有具体的答案, 记录用于自己反思)
- 数据之间的关联和定义是怎样的
- 说到了Java化,举一个例子你是怎么进行Java化的
- 系统边界如何定义的
- 后台的数据展示的时候如何打平展示
- Redis 在项目中的应用场景
- 现在你有一批数据要对外交互, 应该如何进行加密?
- 有什么让你觉得压力特别大的项目吗
- 一个接口特别慢时的排查?
覆盖索引有了解过吗
- 只需要在一棵索引树上就能获取SQL所需的所有查询输出, 无需回表, 速度更快
- 为了实现联合索引, 可以把需要查询的字段, 建立到联合索引里面去(不要无意义的添加, 应该是作为筛选条件添加)
- select count(id) 和 select count(*), 由于id不需要回表, 所以速度相对要快一些
为什么是最左匹配原则
- 基于b+树,从左往右拼接字段,只能产生最左匹配这个结果
Redis为什么快
-
因为基于内存的调用
-
高效的数据结构
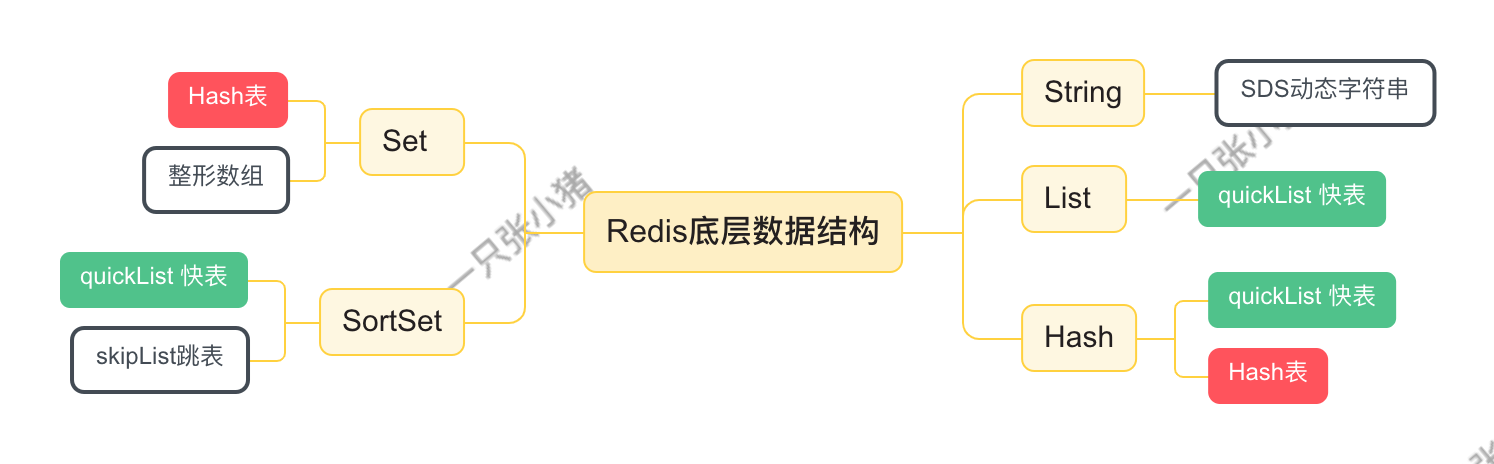
- SDS动态字符串:空间提前分配 + 空间惰性释放
- quickList 快表:新版本中替代 zipList 和 linkedList, 利用LinkedList的双向链表, 存储zipList的头结点
- skipList 跳表
操作系统的 "信号" 有什么了解吗
- 信号是进程之间通信的一种方式,发送方发送内容,指定接收进程,然后发出软件中断,OS接到中断请求后,找到接收进程,通知接收进程处理信号
kill 和 kill -9 有什么区别?
kill和kill -9都用于终止进程, 区别在于:
- kill生成一个结束进程信号, 要求接收进程释放内存或处理对应的子进程
- kill -9 生成一个用户终止进程执行信号, 接收到信号的进程会立即终止进程
具体题目忘记了, 主要是awk在过滤文件内容时的应用
Redis的淘汰策略有了解吗
- 基础两种
- 默认: 定期删除, 但是每秒10次的扫描, 对于大容量存储的Redis来讲会造成巨大的复旦
- 惰性删除: 访问key时, 如果过期会直接进行删除
- 淘汰策略
- noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
- allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
- volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
- allkeys-random:加入键的时候如果过限,从所有key随机删除
- volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
- volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
- volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
- allkeys-lfu:从所有键中驱逐使用频率最少的键
说说LRU
LRU (Least recently used) 最近最少使用
- 新增k-v的时候, 首先在链表结尾添加节点, 如果设置超过阈值就淘汰头结点
- 修改k-v值时, 先修改, 再挪到队尾
- 访问k-v的时候, 移动Node到队尾
自己实现LRU的话怎么实现(其实是问LRU的实现原理)
- 散列表(hashTable) 存储节点位置信息, 做到提升获取速率
- 双向链表存储节点顺序
- 头尾增加哨兵节点, 增加删除节点的时候直接删除

暂无评论