前言
Redis缓存都在用, 但是为什么用, 这个常考的知识点往往除了面试标准答案之外没有更多的回答(导致面试、晋级挂掉). 功利的讲, 本就来看看到底为什么用Redis, Redis为什么 "快".
用于心急时候想吃的热豆腐, 面试的标准简要答案是:
基于内存实现 -> 读写快
独特的数据结构 -> 操作快
单线程 + IO多路复用 -> 避免频繁的上下文切换
自定义协议 -> 解析快(且可读)
基于内存
速度是在对比中产生的, 所以我们先说不基于内存的 "磁盘存储" 是什么样的.
以持久化存储MySQL为例子, 假设我们要找到索引 α 对应的行数据 A, 我们要依次进行:
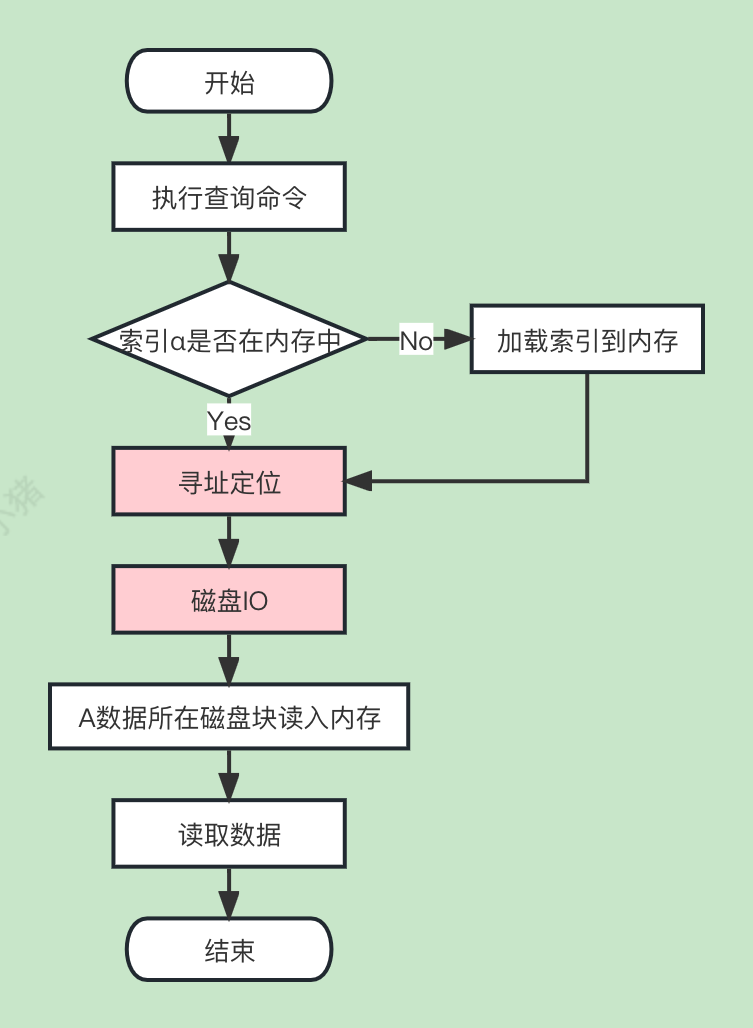
- ·其中红色部分, 如果是机械硬盘还会更慢一些
这么多步骤, 而Redis只需要:
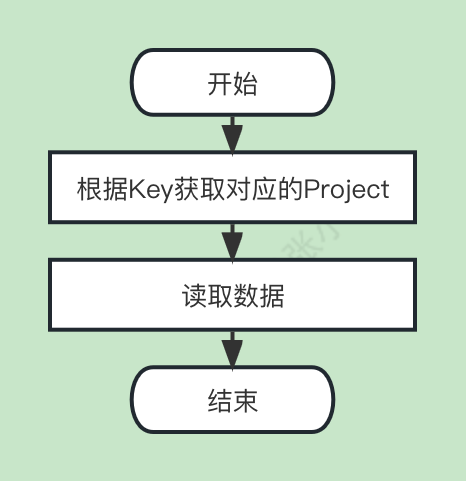
节省了如此多的步骤和IO, 自然是要比硬盘存储快很多的.
读取索引 α 的时候读入的是整个索引再寻找而不是找到单个读入.
独特的数据结构
String
-
·string 是一个可变字节数组.
-
·Redis的字符串预分配冗余空间来减少内存分配(结构类似ArrayList).
-
·string 长度小于1M时, 扩容是直接加倍; 大于1M时, 每次增加1M.
-
·string 最大长度为512M.
-
·常见操作有 get 、 set 、 getrange(获取部分字符串) 、 setrange(覆盖字符串) 、 append 、 expire (设置过期时间) 、 ttl (查看过期时间) 、 del
-
·当string是整数时, 附加操作 incrby (+) 、 decrby (-) 、 incr (+=1) 、 decr (-=1)
整数数字取值范围 [Long.MIN, Long.MAX]
list
-
·quicklist + ziplist 实现, 多个ziplist连接起来组成quicklist.
-
·常见操作有 rpush 、 rpop 、 lpush 、 lpop 、 llen 、 lindex (访问指定位置的元素) 、 lrange (获取子元素列表) 、 lset 、 linsert 、 lrem (删除元素) 、 ltrim (定长列表).
-
·通常作为异步队列使用.
hash
-
·使用数组 + 链表的方式存储(类hashMap), 数组中存储链表的头指针.
-
·

如图所示, hash情况下, 要获取数据先获取Key值的hash数据, 然后对数组取余, 获得链表的头指针之后, 遍历链表获取想要的数据. -
·常见命令: hset 、 hmset (批量set) 、 hget 、 hmget 、 hdel 、 hexists.
-
·扩容的时候扩容为原来的两倍, 并对原有的键值对 rehash.
-
·Redis的rehash的方案会同时保留两个新旧hash数组, 在后续的定时任务以及hash结构的读写指令中将老数组逐渐迁移到新数组中, 避免因扩容导致的卡顿.
-
·当数据不足一半时, 为了节省内存会进行缩容, 直接缩一半.
set
-
·同HashSet和HashMap, Set的实现结构和hash相同, 所有value指向相同值.
-
·常用命令: sadd 、 smembers 、 scard 、 srem 、 spop (随机删除) 、 sismember (是否存在)
zset
常用与否, 这是一个很重要的数据结构, 使用了比较重要的一种数据结构 skipList
常用命令集合:
-
·zadd
- ·eg:
- ·zadd collection testKey 1.0
- ·eg:
-
·zcard(判断长度)
- ·eg:
- ·zcard collection
- ·eg:
-
·zrem(删除元素)
- ·eg:
- ·zrem collection testKey
- ·eg:
-
·zscore(获取指定集合的某个元素的权重)
- ·eg:
- ·zscore collection testKey
- ·eg:
-
·zrank/zrevrank(获取指定集合的某个元素的正向/反向排名)
- ·eg:
- ·zrank collection testKey
- ·eg:
-
·zrange/zrevrange(根据排名获取指定集合范围内的数据 正序/倒序)
- ·eg:
- ·zrange collection 0 5
- ·eg:
-
·zrangebyscore/zrevrangebyscore(根据权重获取指定集合范围内的数据 正序倒序)
- · 可以用±inf表示正负无穷
- · eg:
- · zrangebyscore collection 0 5
- · zrangebyscore collection -inf +inf
skipList
跳表的概念和结构相对比较难于理解(对于我来说是这样的…可能因人而异), 我们一层层的剖析.
第一层
我们假设我们有一个有序链表:
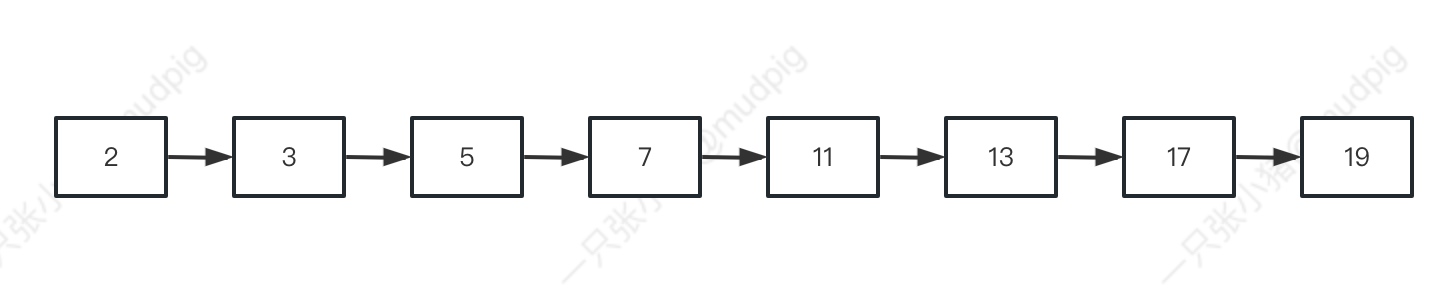
想要找到数据13, 就需要循环遍历: 2->3->5->7->11->13, end.
第二层
如何加快这个进度呢? 添加一级索引:
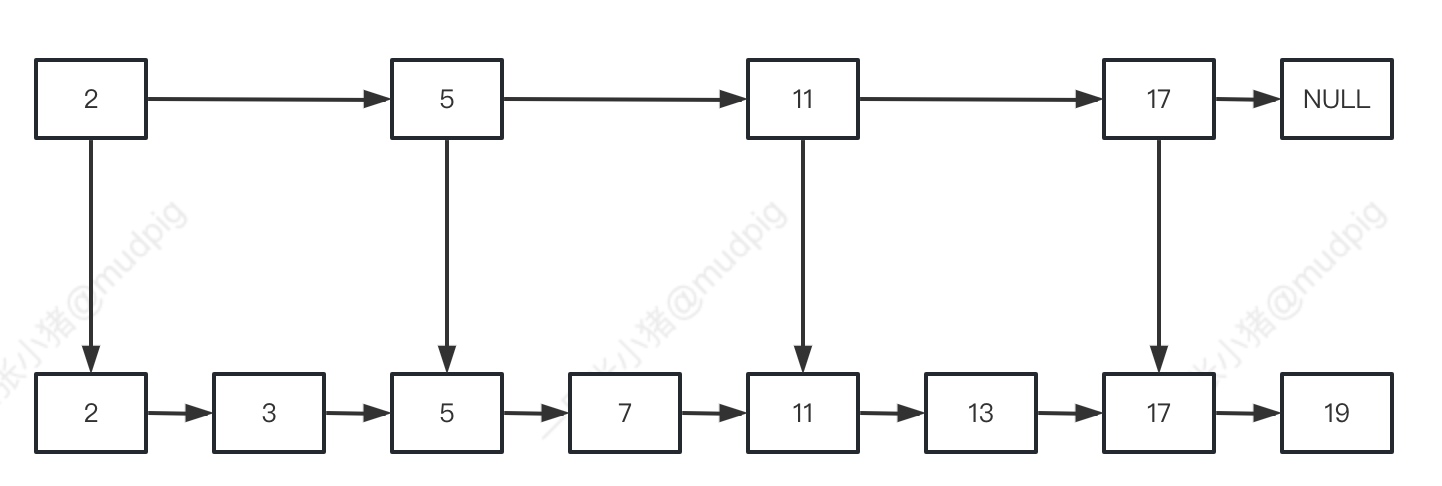
想要找到13, 则先从 "索引" 开始找:
-
- 2 => 不等于13, 且比13小, 跳过
-
- 5 => 不等于13, 且比13小, 跳过
-
- 11 => 不等于13, 且比13小, 跳过
-
- 17 => 不等于13, 比13大, 下落一层从11.next开始找
-
- 13 => 等于13, 返回
第三层
再加一层 "索引"
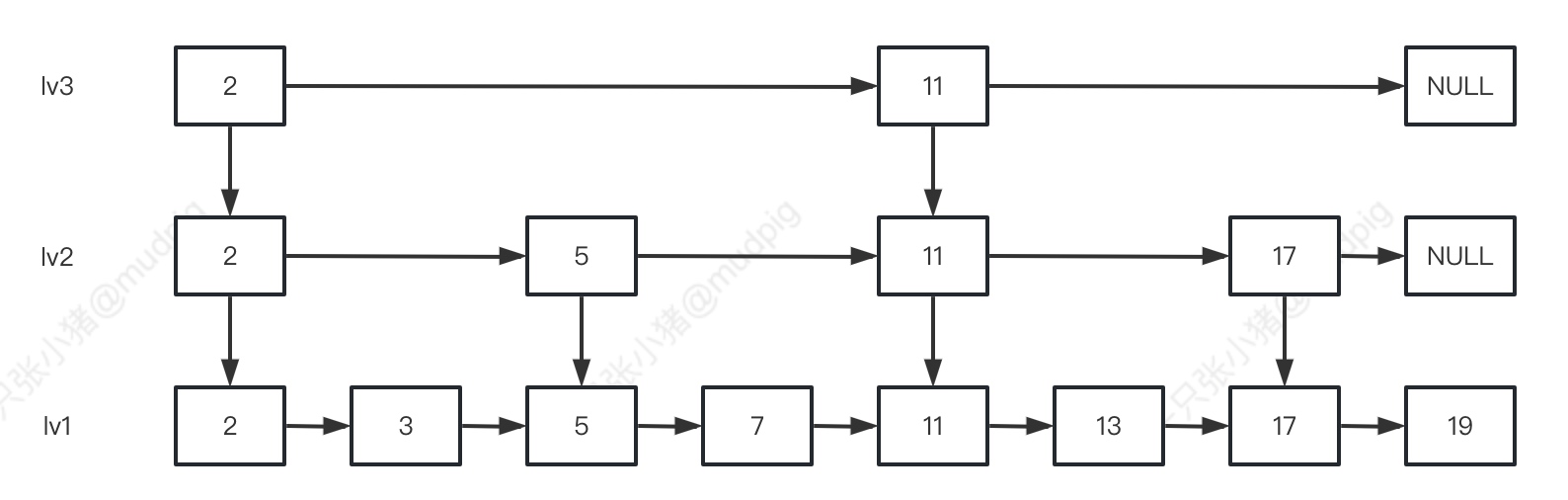
-
- 2 => 不等于13, 且比13小, 跳过
-
- 11 => 不等于13, 且比13小, 且lv3.11.next == NULL, 从lv2.11.next开始
-
- 17 => 不等于13, 比13大, 下落一层从lv1.11.next开始找
-
- 13 => 等于13, 返回
第n层 – 跳表
当lv1, 或者说原链表的数据足够多时, 就可以建立多层索引(因为很麻烦就不画了). 并最终查找到数据是否存在, 这就是跳表的数据检索主要原理.
查询时间复杂度
O(logn) (数学不是特别好, 这里还是记一个答案吧)
跳表的组成
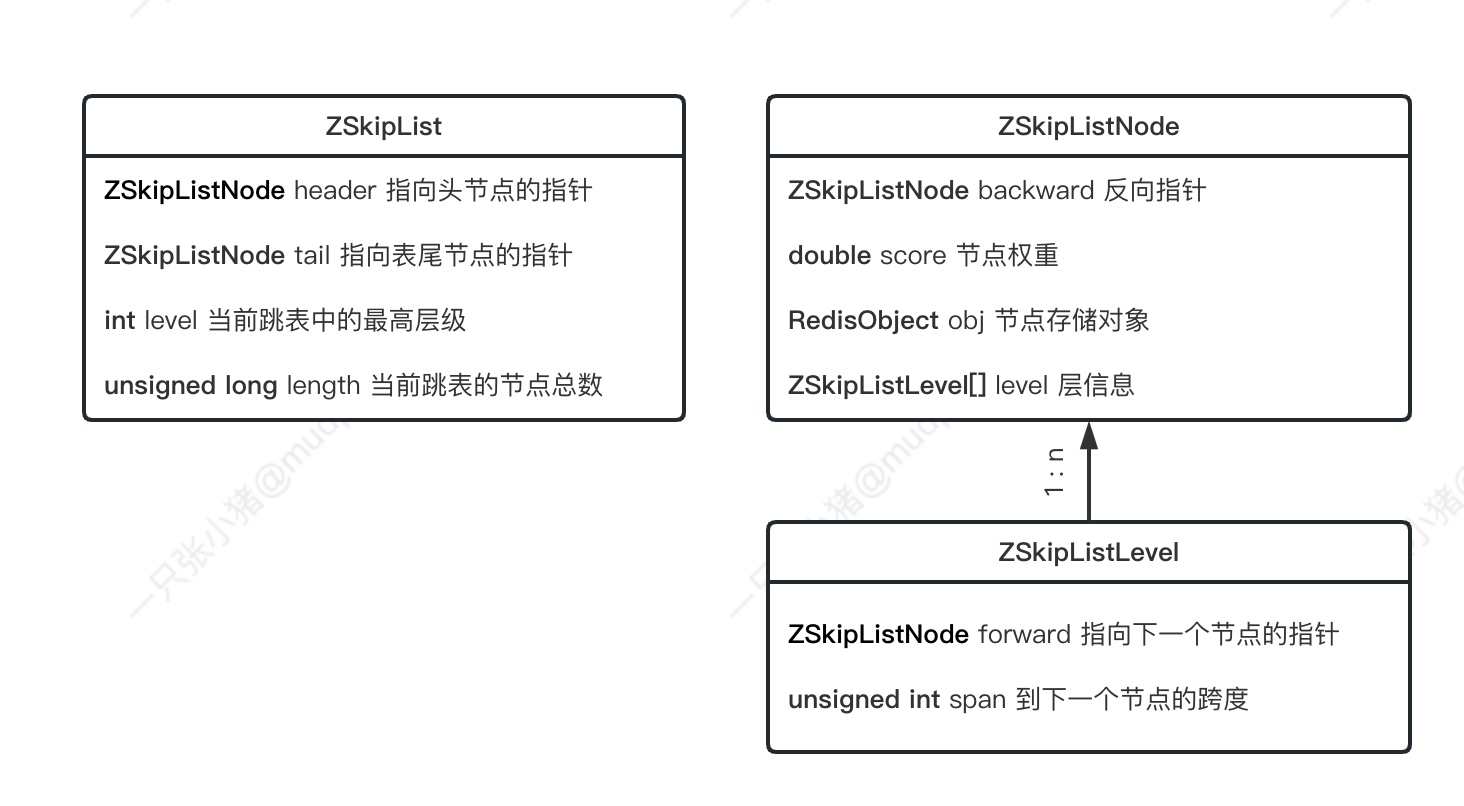
如图, 跳表的元素由三种类信息组合而成:
-
·ZSkipList:
- ·存储跳表整体信息, 用于快速定位、统计.
-
·ZSkipListLevel:
-
·存储单个节点的层信息(对应上文中的 "索引"), 每次创建一个新跳跃表节点的时候,Redis都会根据幂次定律 (简单说就是越大的数出现的概率越小, 这样可以保证高层节点没有低层节点多, 使得跳表每次需要筛选的数据都是越来越少的) 随机生成一个介于 1 和 32 之间的值作为 level 数组的大小(也叫层的高度).
-
·跨度: 记录到达下一个节点所需要经过的节点数, 通常用于计算节点的排序. 比如说, 从header出发, 找到节点node一共经历了4跨度, 那么节点node的排序就是4.
-
楞次定律: wiki传送门
-
·ZSkipListNode:
-
·用于存储单个节点信息.
-
·层: 包含若干个指向其他节点的元素信息.
-
·反向指针: 用于逆向遍历. 需要注意的是, 和拥有多层的前进指针不同, 反向遍历只有一个指针, 所以只能一个节点一个节点的查找.
-
节点之间, 根据权重 (zskipListNode.score) 从小到大进行排列, 当score相同时, 会根据obj字典排序进行排序.
感觉skipList和红黑树都是有序链表, 为啥不用红黑树呢?
并发情况下红黑树插入数据的时候要进行rebalance, 个别情况可能要锁住整个树, skipList锁住个别情况就行了.
单线程
一个说难不难说简单不简单的理解问题: 单线程为啥是优点呢, 我被leader教育的时候单线程是个贬义词啊.
其实这里我们要区分并发和并行的概念:
-
·并发: 同一时间段多个进程只有一个在执行 -> 多个进程指令不同时间段, 被极快的轮换执行, 看上去好像都在执行的样子.
-
·并行: 同一时间段多个进程都在执行 -> 齐头并进的处理.
并发过程中, 为了保证切换回来的时候能够继续进行, 是要在退出之前保存好对应的状态的, 而且再加载状态开始执行也需要一定的时间(这个过程也被称为 上下文切换). 在计算量 / 计算时间不够大的时候, 这种时间消耗在一定程度上其实是会阻碍进度的.
举例来说, 假设你有两个项目需要上线:
-
·多线程场景下, 你规划每天先做1min项目A, 再做1min项目B, 来回切换着做, 好像两个项目都在进行. 而上下文切换损耗, 就是项目A到项目B(或者反过来), 你需要回想刚才写到哪的时间.
-
·单线程场景下, 你先做完项目A, 再做项目B.
例子虽然比较极端, 但是哪种方案效率更高效果更好, 不言而喻.
所以说, 在Redis的场景下, 一条命令从头直接执行到返回, 通过单线程的方式抹去了上下文切换的时间损耗, 这也是快的原因之一.
Redis的单线程, 不是说一个Server只有一个线程处理程序提交的网络请求.
为了保证CPU利用率最大化, 可以在一台机器节点上启动多个Redis.
多路复用IO
IO模型都有什么
阻塞IO
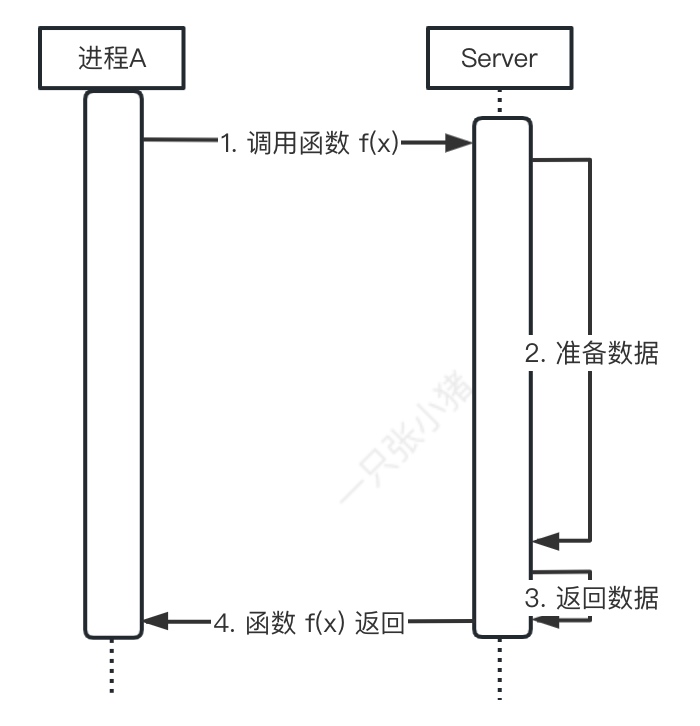
如图, 阻塞模型就是进程A在调用Sever的f(x)函数时, 1~4 的时间区间都处于阻塞状态, 不能处理、接收、发送其他的指令, 且受到断开的影响.
非阻塞IO
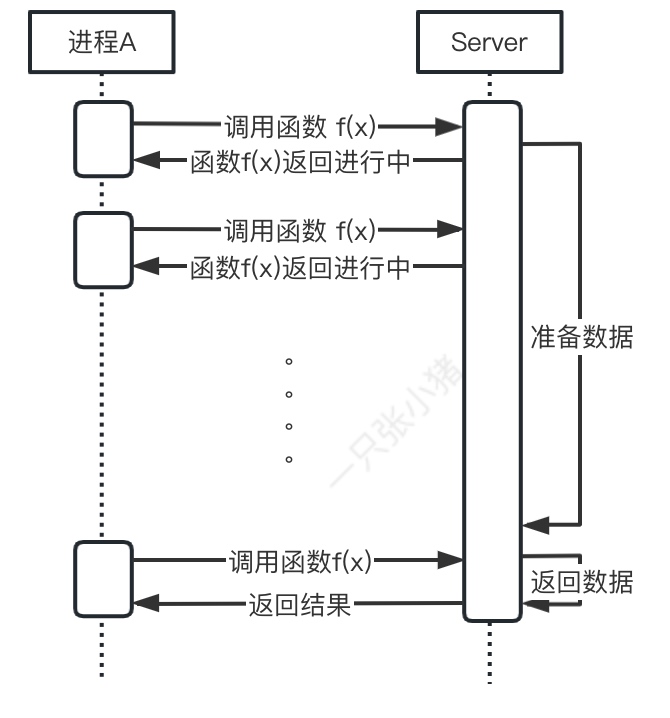
如图, 相同的调用一个函数, 在Sever端还在处理的时候, 非阻塞IO下的进程请求会立刻收到暂时没有数据返回的状态, 可以准备再次发起请求, 直到成功获取返回值, 或者到达等待上限.
多路复用IO
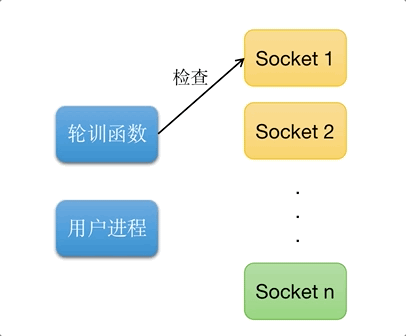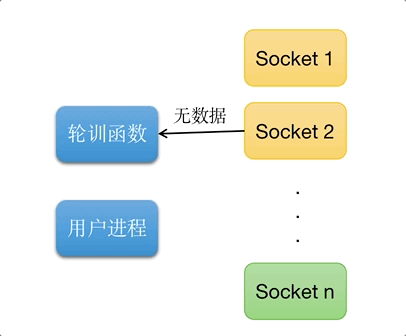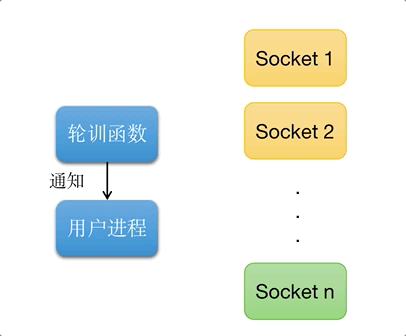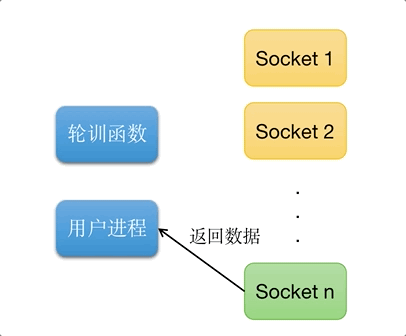
多路复用IO, 又称事件驱动IO(Reactor设计模式). 如图所示, 可以同时处理多个请求链接, 当轮训函数检查到的socket链接准备好返回的时候, 通知进程获取数据.
异步IO
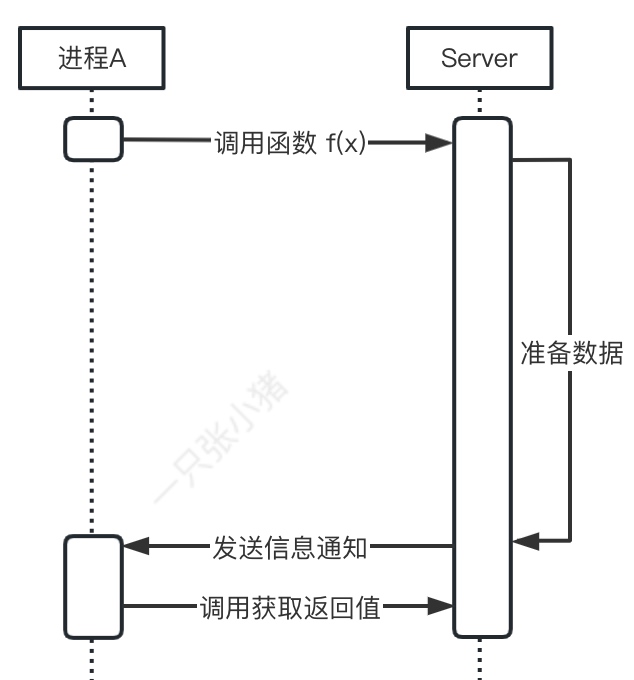
异步IO, IO中Proactor设计模式的体现. 进程调用函数之后, 可以直接去处理其他请求, 等到Server端处理完成后, 会主动通知进程获取对应的返回值.
Redis是怎么用IO的?
-
·Redis的IO多路复用程序, 是通过包装常用函数库实现的(select、epoll…)
-
·Redis为每套函数库都实现了相同的API(比如说select、epoll两种函数都实现了set、del、get方法), 编译的时候会根据当前OS选择不同的函数库进行 include.
-
·Redis基于IO多路复用的Reactor模式, 设计了独特的请求处理方式: "文件时间处理器":
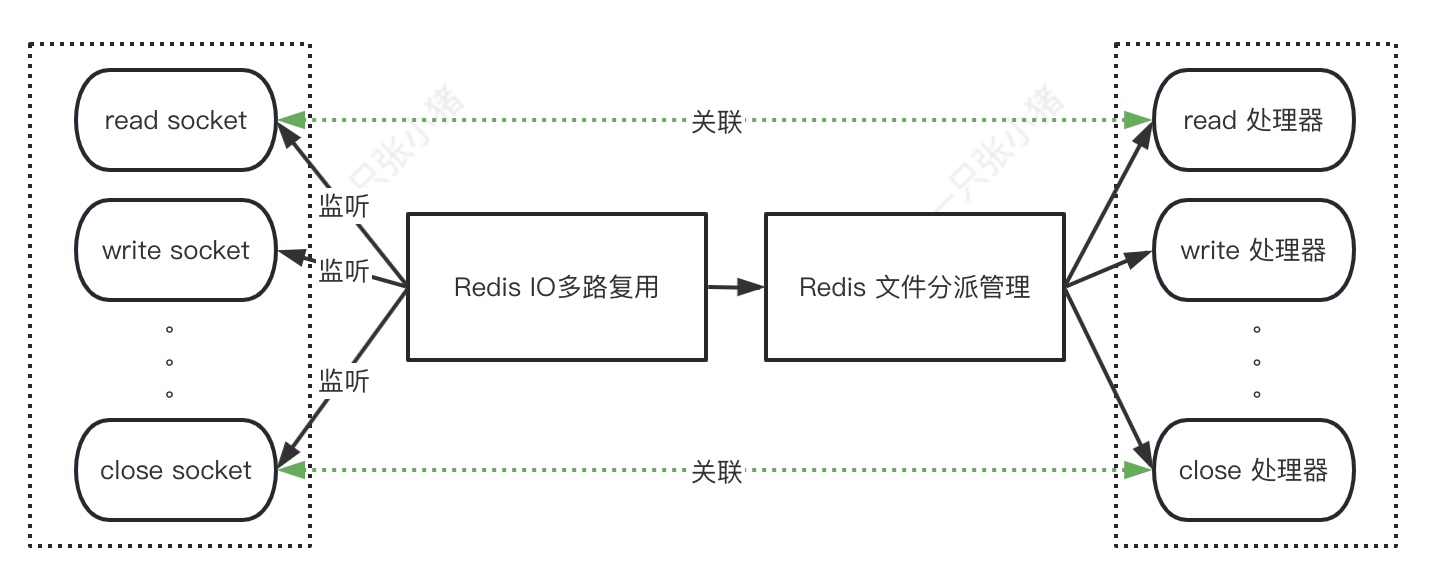
如图所示, Redis采用IO多路复用监听多个不同的socket, 并通过文件分派管理给他们关联不同的文件处理器, 类似于IO多路复用的模式, 当一个socket准备好处理时, 关联的文件处理器就开始工作.
RedisIO多路复用部分采用队列接收, 每次给文件分派管理部分发送一个事件, 分配完了才会发送下一个
自定义协议
-
·Redis自定义了 "RESP" 作为自己的网络通讯协议.
-
·RESP 支持的数据结构有 简单字符串、错误、整数、批量字符串、数组.
-
·RESP 的请求: client端将命令作为批量字符串的RESP数组发送到server端.
-
·RESP 的响应: server端根据传入的命令不同以不同的RESP类型数据进行回复.
-
RESP响应数据中, 第一个字节的内容决定了返回数据的数据类型
有多快?
官方数据中, 60000 client连接的情况下, Redis能保持 50000qps, 是持久化应用不可企及的高度.

暂无评论